
この記事の目次
windowsとunicode環境とのやり取りで発生?
文字コードを使って回避できるのか
1995年あたりまでは、プログラミング言語で使う文字コードはShift_JISがかなり主流となっていました。
windowsはshift_jis、linux系はeucといった感じでしょうか。
ところが、2000年前後になると、shift_jisではなくunicodeで文字列を扱うケースが多くなりました。
それに伴い、古いプログラミング言語で作られたシステムと、比較的新しいプログラム言語で作られたシステムの間で、文字コードの相違による文字化けが多発するようになりました。
古いシステムの代表例は、1990年代に多くのシステム開発で利用されたVisual Basic, Visual C++などがあります。これらでは多くの場合、Shift_JISが利用されていました。
これらのシステムと現在主流のシステム(unicode環境)とデータやり取りする場合、文字化けが発生します。ただ、残念なことに、それぞれの文字コード特有の文字も多く、簡単に文字コードの変換ができません。
どのように文字化け対策をするのか
ではどのように文字化け対策をするのか。
これは非常に大きな課題ですが、基本的には文字化けは避けることができません。
そのため、対策としては、文字化けが考えられる、または文字化けしてしまった文字の文字コードを対応する文字の文字コードにリプレイスすることにより回避します。
仮に対応する文字がない場合は、その文字コードを旧システムで利用する場合、大体の文字で置き換えるか、空としてスキップする必要が発生します。
上記の対策は一見、手がかかり、解決策になっていないように感じるかもしれませんが、システム運用していくと、文字化けが徐々になくなっていき、最終的にはめったに文字化けが発生しないようになります。
ようは、必要になった時点で文字コードを置き換え続けていくと、文字化けする文字がなくなっていくイメージです。
文字コードを置き換えよう
ではどのように文字コードを置き換えるのか説明します。
下記のコードをご覧ください。
str = Replace(str, ChrW(&H24B6), "A")
str = Replace(str, ChrW(&H2460), "①")
1行目は、Aという文字をAに置き換え、2行目は丸1を丸1に置き換えています。
ChrWの中のコードがunicodeとなります。
これらを文字化けする度に追加していきます。
では実際に文字化けした文字のunicodeが何なのかを確認するのはどうするの?
という疑問がでてきます。
そのためには、wordを使います。
wordを使った文字コードの確認
手軽に文字コードを確認する方法を紹介
表示されている文字の文字コードを確認するには、いろいろなフリーのソフトがありますが、もっとも簡単に確認できる方法があります。
それは、wordを使います。
まず、wordを起動します。
試しに「あいうえお」を入力します。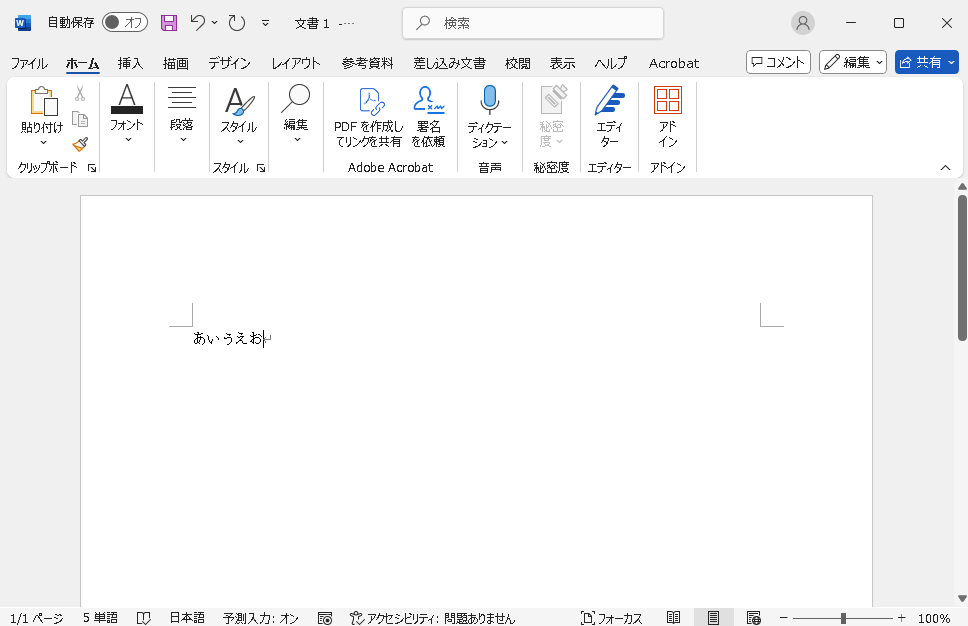
ここで「う」の文字コードが何かを調べます。
カーソルを「う」と「え」の間に置きます。つまり、調べたい文字の後ろにカーソルを置きます。
その状態で、Alt+Xキーを押します。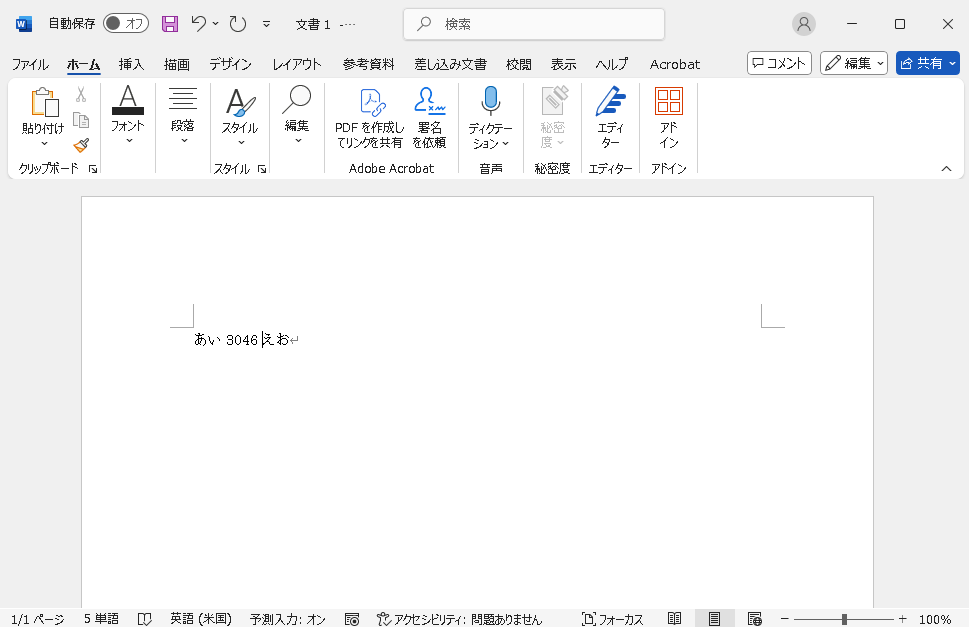
どうでしょう。
「う」が「3046」に変わりました。
つまり、「う」のunicodeは「3046」ということになります。
まとめ
いかがでしょうか。
文字化けはプログラムを作っていて必ず出会う壁かと思います。
文字コード変換のライブラリが提供されているケースでは問題ありませんが、提供されていない場合は、上記のように、特定の文字コードを他の文字コードに置き換えるということも検討ください。